uKernel DevLog #1
Avg. 7 minute(s) of readingI'm currently enrolled in a class about embedded and real-time systems. For this class's final project, I'm developing a real-time kernel for Arduino UNO. I'll try to document the development in a series of posts. This is part #1.
Today (as of writing) was the exam's day: the final exam was in the middle of the semester. As such, the rest of lectures are reserved for the development of the project. My team (me and 2 friends) decided to develop a micro-kernel (uKernel) for the Arduino UNO. The Arduino wasn't chosen for any reason in particular (besides being available at the school's lab).
The basics
Around 2 weeks ago, we had a guided workshop to develop a small Kernel for the Arduino (in C). It was a tick-based preemptive kernel supporting a fixed task-set of periodic tasks with fixed priorities. This kernel had both a scheduler and a dispatcher, so we had what's called on-line scheduling. The tasks' deadlines are equal to their periods.
Explaining concepts
- Task - A set of instructions that has to be run according to some time constraints;
- Periodic task - A task that takes C time units to complete and needs to
be run every T time units;
- Note that this doesn't mean that a task (C=2ms, T=10ms) executes for 2ms and then executes again, that 10ms later. It means that every 10ms, 2ms will be taken to execute the task.
- Period (T) - The time between task activations.
- Fixed priorities - A static attribute assigned to each task:
- Higher numbers mean higher priority;
- Used by the scheduler to choose which task to run at a given instant.
- Tick-based - A tick-based kernel (like the name implies) uses timer interrupts to schedule and dispatch tasks;
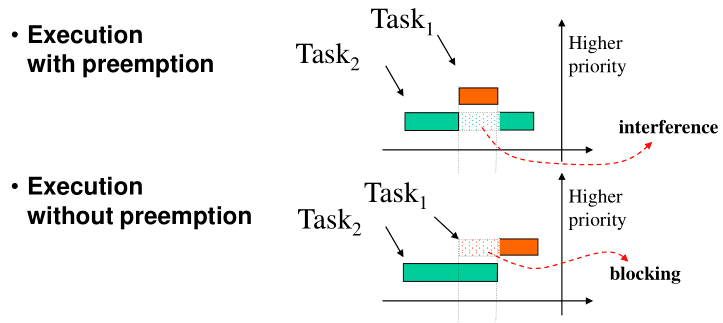
- Preemptive - When a kernel supports preemption, it means that tasks can be paused
Source code
1#define NT 20 // the max number of tasks in the system 2 3typedef struct 4{ 5 unsigned int period; 6 unsigned int delay; 7 void (*func)(void); 8 unsigned int exec; 9} Task; 10 11Task tasks[NT]; 12unsigned int curr_task = NT + 1; 13 14/* 15 * Registers a task in the system. The delay controls the initial offset of the task. 16 * A task with 0 period is only run once (one-shot task). 17 */ 18int Sched_Add(unsigned int period, unsigned int delay, void (*func)(void), unsigned prio) { 19 if (!tasks[prio].func) { 20 tasks[prio] = { 21 period, 22 delay, 23 func, 24 (delay == 0) 25 }; 26 return prio; 27 } 28 return -1; 29} 30 31/* Ticks all tasks: updates the current time till ativation, and sets tasks ready */ 32void Sched_Schedule() { 33 for (int i = 0; i < NT; ++i ) { 34 if (!tasks[i].func || tasks[i].exec) 35 continue; 36 37 if (tasks[i].delay == 0) { 38 tasks[i].exec = 1; 39 tasks[i].delay = tasks[i].period + 1; 40 } 41 --tasks[i].delay; 42 } 43} 44 45/* Runs the highest priority ready task */ 46void Sched_Dispatch() { 47 int prev_task = curr_task; 48 49 for (int i = 0; i < prev_task; ++i) { 50 if (tasks[i].func && tasks[i].exec) { 51 tasks[i].exec = 0; 52 53 // run task 54 curr_task = i; 55 interrupts(); 56 tasks[i].func(); 57 noInterrupts(); 58 curr_task = prev_task; 59 60 // delete one-shot tasks (tasks that only run once) 61 if (tasks[i].period == 0) { 62 tasks[i].func = 0; 63 } 64 } 65 } 66} 67 68// Timer1 interrupt handler 69ISR(TIMER1_COMPA_vect) { 70 Sched_Schedule(); 71 Sched_Dispatch(); 72} 73 74void setup(){ 75 Sched_Add(10, 5, FuncX, 0); 76 Sched_Add(4, 0, FuncY, 1); 77 Sched_Add(1, 0, FuncZ, 2); 78 79 // Setup timer interrupts on timer1 80} 81 82void loop(){ 83 // do nothing 84}
In the code above, I've omitted some details like the implementation of the
tasks function (FuncX, FuncY, FuncZ just toggle their respective LED) and
how to set up timer interrupts, for simplicity’s sake.
Code analysis
Given how scary "implementing a micro-kernel" sounds, the code above is fairly simple. In my opinion, the most elegant part is how preemption is handled:
- When handling an interrupt, interrupts are automatically disabled (and re-enabled on return from the interrupt handler);
- Before running the task's code, we re-enable interrupts (and disable them afterwards);
- If the task is long enough for another timer interrupt to happen, the ISR can start executing another task;
- When a task returns, and the ISR exits, the previous task's execution will be resumed.
Another cool property is how task overruns are handled. A task overrun
is when a task runs for longer than the maximum time (worst-case) it said it
would run for. In the case of this micro-kernel, the task's deadlines are
equal to the periods (Di = Ti). If a task runs for longer than its period,
it can't prempt itself. The cool thing about this is that the effect of these
overruns is deterministic: they only affect tasks of lower priority
(they get delayed).
But there are some problems with this implementation:
- The kernel uses fixed priorities, but they aren't sorted in any particular order. This makes schedulability testing unfeasible;
- We can't configure a task to have deadlines smaller than its period
(
Di < Ti); - The tasks are assumed independent, so there aren't priority inversion (blocking) problems with the kernel;
- For the same reason, task synchronization (semaphores)/mutual exclusion (mutexes) mechanisms aren't available.
Improving the kernel
Task schedulability
When we have a real-time system, we're interested in determining if the task set can be scheduled in a way that no deadlines are missed before deploying the system.
In the case of this kernel (considering fixed priorities and Di = Ti), there
are 2 alternative methods for priority assignment:
- Rate Monotonic (RM) - The priorities are inversely proportional to the
period. This means that the lower the period, the higher the
priority. Only works for
Di = Ti; - Deadline Monotonic (DM) - The priorities are inversely proportional to the
deadline. This means that the lower the deadline, the higher the
priority. Works for
Di <= Ti.
Let's the following task set with RM priorities:
| priority | T | C |
|---|---|---|
| 1 | 2 | 0.5 |
| 2 | 3 | 0.5 |
| 3 | 6 | 2 |
The lower the priority, the higher the period (T). C is the amount of CPU time the task needs to complete execution (worst-case).
To verify the schedulability of this task-set, we perform a CPU utilization test using Liu & Layland's Least Upper Bound (LUB):
- CPU utilization - U(n) - Is the sum of all tasks utilization:
Ci/Ti; - LUB -
n * (2^(1/n) - 1), wherenis the number of tasks in the system. U(n) > 1=> non schedulable set (overload);U(n) <= LUB=> schedulable set;1 >= U(n) >= LUB=> undetermined case. The test doesn't always work/grantee if the system is schedulable/unschedulable.
The image below shows this test being applied to the task-set above.
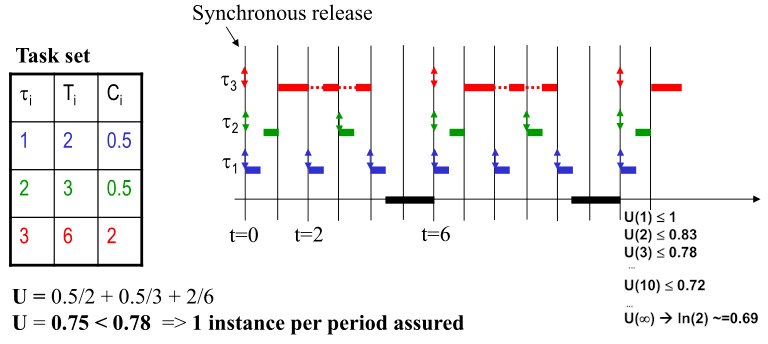
As the image displays, the task-set is schedulable.
Harmonic periods – special case
If the periods of all tasks are harmonic (all multiples of each other), we
compare the CPU utilization to 100% (instead of the LUB): U(n) <= 1.
It should be noted that, if the periods aren't harmonic, we can't grantee 100% CPU utilization with fixed priority systems.
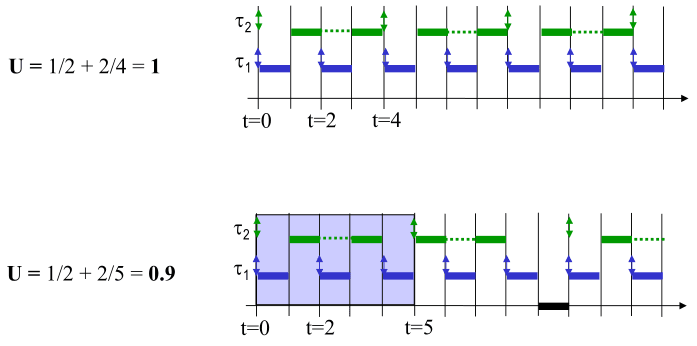
In the image above, we have 2 systems with 2 tasks each:
- In the first system, the periods are harmonic. The tasks use 100% of the CPU, and the task-set is schedulable;
- In the second system, the periods aren't harmonic. In fact, there is less "load" in the system as the second task has more slack (doesn't run as often). Still, we aren't using 100% of the CPU and if we reduce the period of any of the tasks for any amount (make them more frequent), the task-set won't be schedulable.
To solve the problem above, we can use dynamic priority systems: a task's priority is only known/calculated at run-time by the scheduler.
Blocking situations
Blocking happens there are dependencies/sequences between tasks.
For example, 2 tasks share a mutex for a given critical region. Task 1
(higher priority), tries to preempt task 2, but can't execute, because the
mutex is locked in task 2's critical region. In this kind of situation,
task 1 can run for a while before reaching the critical region, but when it
reaches the region, it will have to return control to task 2 before
proceeding.
When this happens, we're going back on our chain of tasks. This means that when the control returns to the lower priority task, it can override that higher priority's stack data (for example, by calling a function).
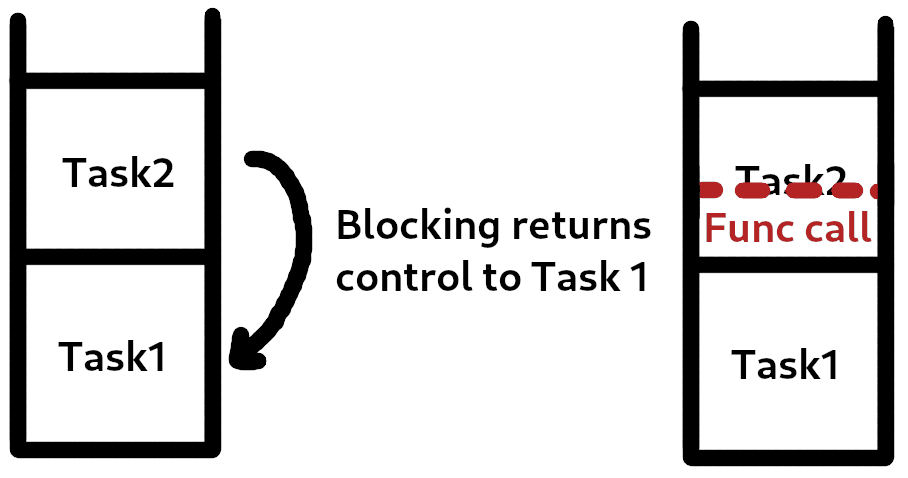
In the image above, we see how a function call from the lower priority task (after blocking the higher priority one) can corrupt the stack.
To deal with this, we'll implement mechanisms to manage the access to shared resources, and their protection mechanisms. Most of these solutions require us to implement multiple stacks: one for each task.
Shared resource access
There are several solutions available to us here depending on which techniques of shared resource access control we want to implement. These techniques divide themselves into 2 main groups:
- Global - Interrupt disabling and/or preemption disabling. These are only feasible for extremely small critical regions as they block the whole system. We won't really deal with this in our implementation.
- Local - Mutexes and semaphores.
The local methods are more efficient, but they can introduce some other problems, namely: undetermined blocking, chained blocking, and deadlocks. The protection mechanisms intend to mitigate one or more of these. We'll explore these in the future (when we're implementing them).
Conclusion
I tried to explain most of what I find the fundamental concepts of Real-time systems, so next posts can be easier to follow. I hope it wasn't too much.
In the next chapter, we'll explore how we can implement multiple stacks: one for each task. Spoiler: there's assembly involved. We'll also start using C++ where we can, so we can clean up the code by using classes.
Stay safe :P